
Reinforcement Learning: Training Machines to Make Smart Decisions
Imagine teaching a dog to fetch. You throw a ball. If it brings it back, you give it a treat (a reward). If it gets distracted and chases a squirrel, there's no treat (a lack of reward). Over many attempts, the dog learns that the action "bring ball back" leads to the best outcome. This simple, powerful process of learning through trial and error is exactly how we are teaching machines to make smart decisions.
This method is the heart of Reinforcement Learning (RL), a thrilling field of Artificial Intelligence that allows an AI agent to learn optimal behavior on its own, simply by interacting with an environment and trying to achieve a goal. It's the science behind an AI mastering the world's most complex games and a robot learning to walk without being explicitly programmed for every step.
This guide will demystify Reinforcement Learning. We'll break down its core components, explore the learning process, and showcase the incredible ways it is already changing our world.

What is Reinforcement Learning? The Third Pillar of Machine Learning
Reinforcement Learning is one of the three main paradigms of machine learning, each with a unique approach to learning from data. To understand RL, it helps to know what it's not. For a full breakdown, you can read our guide on AI, Machine Learning, and Deep Learning, but here's a quick summary:
- Supervised Learning learns from a dataset that is fully labeled, like a student studying with an answer key. It's great for classification and prediction.
- Unsupervised Learning is given unlabeled data and must find hidden structures or patterns on its own, like a detective looking for clues without knowing the crime.
- Reinforcement Learning learns by doing. It forges its own path through trial and error, driven by a simple goal: maximize its total reward. There is no answer key, only feedback from its actions.
The Core Components of Reinforcement Learning
To understand the RL process, you need to know the key players. The entire system can be described by a few core components, as detailed in the foundational textbook on the subject. Let's use the example of Pac-Man to make them clear:
- The Agent: This is the learner and decision-maker. In our example, the Agent is Pac-Man itself.
- The Environment: This is the world the Agent interacts with. For Pac-Man, it's the maze, including the pellets, power-ups, and ghosts.
- The State (S): This is a specific snapshot of the environment. A state could be Pac-Man's location, the ghosts' locations, and which pellets are left.
- The Action (A): This is one of the possible moves the Agent can make from a given state. Pac-Man's actions are simple: up, down, left, or right.
- The Reward (R): This is the feedback the Agent receives after taking an action. Eating a pellet gives a +10 reward. Getting caught by a ghost gives a -500 reward (a punishment).
- The Policy (π): This is the Agent's "brain" or strategy. It dictates which action the Agent will choose in a given state. The entire goal of Reinforcement Learning is to find the optimal policy that maximizes the total reward over time.
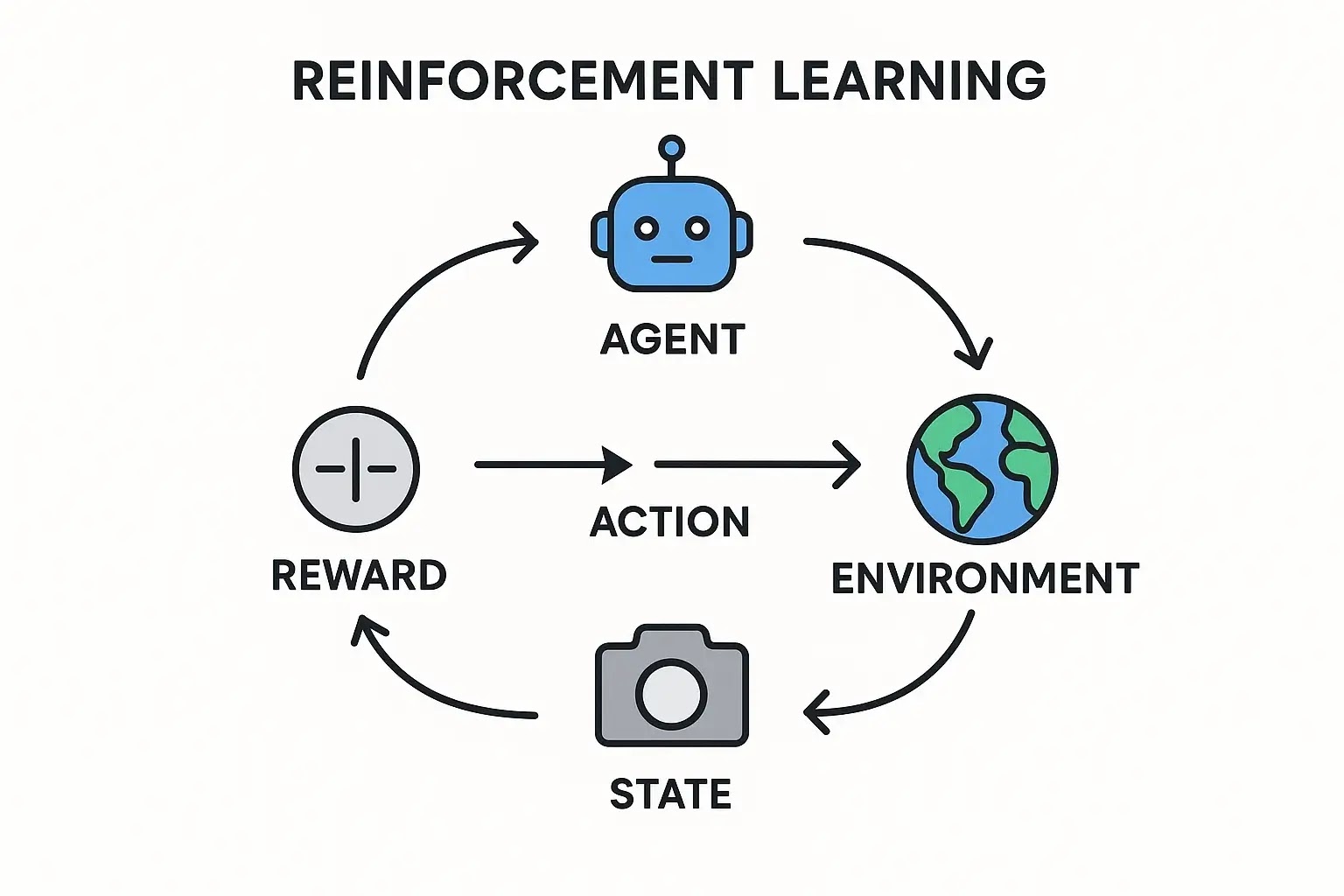
The Learning Loop: Trial, Error, and Triumph
The learning process in RL is a continuous cycle. It works like this:
- The Agent observes the current state of the environment.
- Based on its policy, it chooses an action.
- It performs the action and the environment gives it a reward and a new state.
- The Agent uses this reward feedback to update and improve its policy.
- Repeat millions of times.
A crucial part of this loop is the Exploration vs. Exploitation trade-off. The Agent has to decide whether to "exploit" its current knowledge by taking the action it thinks is best, or to "explore" by trying a random action to see if it might lead to an even better reward. Finding the right balance is key to learning effectively.
Where RL Shines: Real-World Applications
While it might sound abstract, Reinforcement Learning is already solving incredibly complex problems in the real world.

- Gaming and Strategy: The most famous example is DeepMind's AlphaGo, which used RL for Mastering the game of Go and defeating world champion Lee Sedol. It discovered strategies that human players had not conceived of in thousands of years.
- Robotics: RL is ideal for Training robots to walk, grasp objects, and interact with the physical world. Instead of manually programming every joint movement, engineers can define a goal (e.g., "walk across the room"), and let the robot learn the most efficient way to do it.
- Resource Management: Companies like Google use RL to optimize the cooling systems in their massive data centers, saving huge amounts of energy. It's also used in finance for developing automated algorithmic trading strategies.
- Personalized Recommendations: While many recommendation systems are static, RL can create dynamic systems that adjust their suggestions in real-time based on a user's immediate interactions, providing a more relevant experience.
The Challenges and Future of Reinforcement Learning
Reinforcement Learning is not a magic bullet. It comes with a unique set of challenges that researchers are actively working to solve. It often requires millions of trial-and-error attempts to learn, which can be impractical in the real world. Designing a good reward function is also difficult—an agent might find an unintended "loophole" to get rewards without achieving the actual goal, a problem known as "reward hacking."
The future is bright, however. The combination of RL with deep neural networks, known as Deep Reinforcement Learning (DRL), allows agents to learn from raw sensory input like pixels from a screen, leading to the breakthroughs seen in AlphaGo and modern robotics.

Frequently Asked Questions (FAQ)
Q1: How is RL different from other types of machine learning?
A: The key difference is the feedback loop. Supervised learning learns from a static, labeled dataset. RL learns dynamically through interaction with an environment to maximize a long-term reward. It's about strategy, not just pattern recognition.
Q2: Is Reinforcement Learning used in ChatGPT?
A: Yes, a crucial technique called Reinforcement Learning from Human Feedback (RLHF) is used. After initial training, human reviewers rank different AI-generated responses. An RL model is then trained to produce responses that are more likely to receive a high rank, making the chatbot more helpful and safer.
Q3: Can I use RL for my business problem?
A: It depends. If your problem involves a sequence of decisions in a dynamic environment where the outcome of an action isn't immediately clear (like inventory management, ad placement, or robotics), RL could be a powerful solution. For simple classification or prediction tasks, supervised learning is usually better.
Conclusion: The Dawn of Self-Learning Machines
Reinforcement Learning represents a fundamental shift in how we build intelligent systems. It moves us away from a world where we must provide all the answers, and towards a world where we simply define the goal and let the machine discover the best path to get there.
From mastering ancient games to navigating the physical world, RL is teaching machines to learn not just from data, but from experience. It's the dawn of a new era of truly autonomous, adaptive, and goal-driven AI.
Call to Action: Fascinated by how AI mastered the world's most complex games? Dive deeper into the specific strategies and breakthroughs in our detailed article on Reinforcement Learning in Gaming: Winning Strategies!